
Georgios Spithourakis
PhD CompSci ML AI NLP ConvAI
PhD CompSci ML AI NLP ConvAI
• Interested in natural language processing, computational linguistics, machine learning,
deep learning, neural networks, numerical reasoning, conversation modelling, and forecasting.
• PhD in Computer Science at
the Machine Reading Group
of University College London (UCL),
supervised by
Sebastian Riedel.
• Investigating how to improve language models
by including numerical attributes as input features
and by explicitly modelling the output of numerical tokens.
• Funded by the
Farr Institute of Health Informatics Research.
• PhD in Natural Language Processing, UCL.
Thesis: “Numeracy of Language Models: Joint Modelling of Words and Numbers”.
• MSc in Computational Statistics and Machine Learning, UCL.
• BSc/MSc diploma in Electrical and Computer Engineering,
National Technical University of Athens (NTUA).
• Machine Learning Engineer & Scientist at PolyAI (since 2018).
• Teaching Assistant for NLP and web/mobile app development modules
at the Department of Computer Science at UCL (2013-2017).
• Research Scientist Intern at Amazon Cambridge (8 months, 2016) and Microsoft Research (3 months, 2015),
where I worked on question answering for dialogue systems and grounded conversation modelling, respectively.
• Research Associate/ Research Assistant/ Software Engineer at the
Forecasting and Strategy Unit at NTUA (2009-2012).
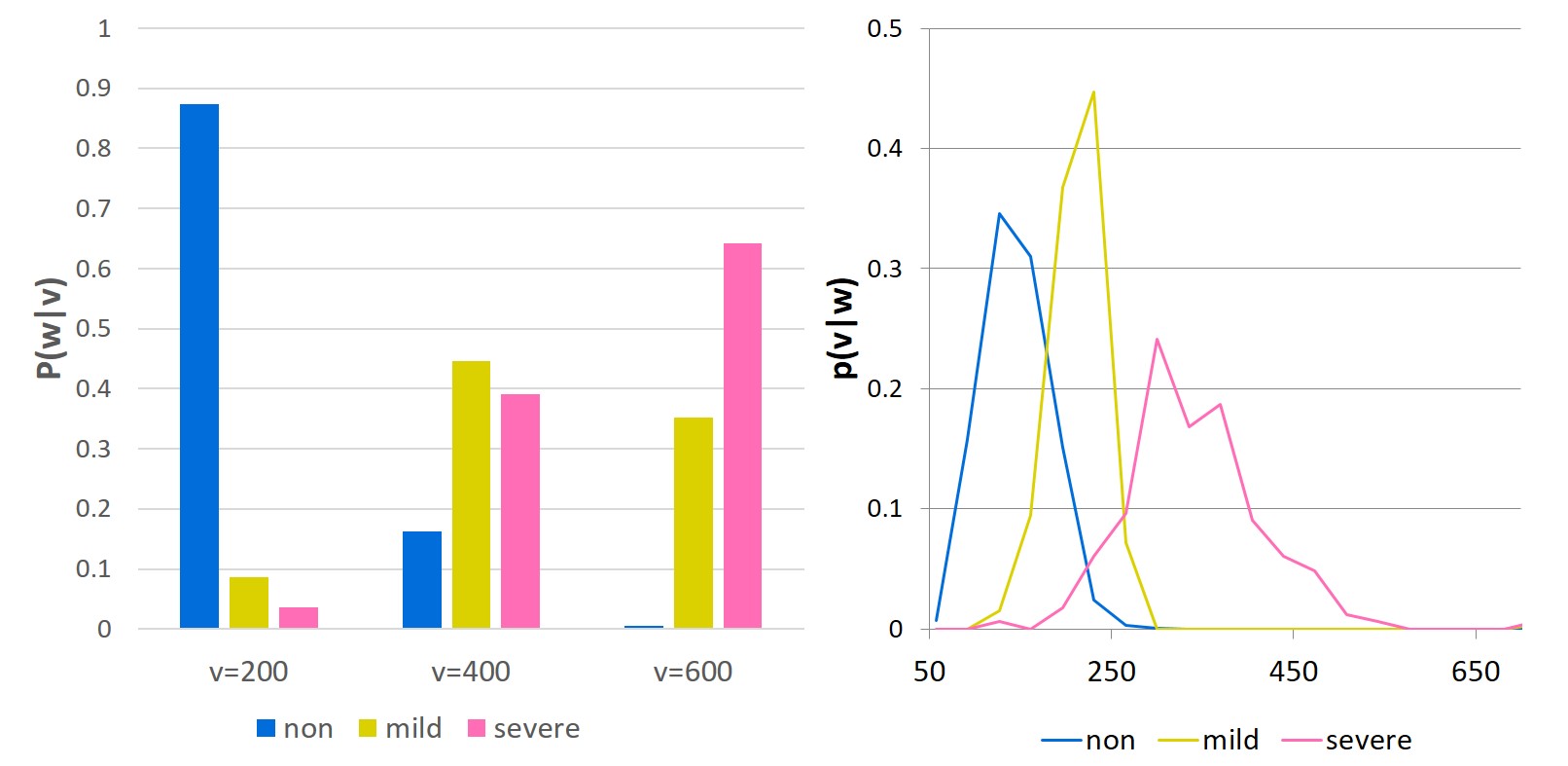
Text often contains numbers to convey specific information in various domains,
e.g. from everyday life ("John is 1.75 meters tall")
to scientific and clinical documents ("severe dilation of the left ventricle with EDV=355ml").
There is a relation between the words and numbers we use, as seen in the figure above.
In this example, we have extracted from clinical reports pairs of numbers (clinical measurements) and words (descriptions of severity of a clinical condition: "non", "mild", "severe") and estimated the distribution of words given numbers and that of numbers given words.
In language modelling, most numbers are often treated as out-of-vocabulary words (or masked under an "UNKNOWN NUMBER" category) and, thus, their informational content is lost. The goal of this project is to investigate and evaluate extensions to language models that allow them to incorporate numeric information.
We find that extending the input of language models to include the magnitude of numeric tokens can lead to improvements in perplexity and the downstream tasks of semantic error correction
(Spithourakis et al., 2016a)
and text prediction
(Spithourakis et al., 2016b).

Together with poet Zena Edwards
we have sought to explore the spectrum between artificial and human creativity.
We have already organised
two
masterclasses,
where participants have created poems through traditional poetry writing exercises (e.g. freeflow, ekphrasis)
and through an AI-inspired interactive simulation,
where participants pretended to be neurons in a poetry-generating artificial neural network.
The events have also included invited talks and performances by
improv theatre human/AI duet Piotr Mirowski and A.L.E.X.,
musician Xana,
tech poet Dan Simpson, and
academic and language expert Mandana Seyfeddinipur.
This project has been supported by Apples and Snakes (a big thanks to Daniela Paolucci!)
and UCL's public engagement "Train and Engage" programme.
More information can be found on Zena's
Tumblr,
blog, and
website.
g.{LastName}@cs.ucl.ac.uk
1st Floor
90 High Holborn
London, WC1V 6LJ
United Kingdom
University College London
Dept. of Computer Science (1ES)
Gower Street
London WC1E 6BT
United Kingdom